OnyxOS Updated to Release 5.3
OnyxOS(AWS) 1.0
Data Ingestion Pipelines – General
-
Preprocessing audit error logging change -
a. Added pipeline type condition for Formulary.
b. Added count variable to count unique row count.
- GlobalVariables.py - reading Cloud watch channel from common functions library.
-
Reporting Dashboard changes -
a. Added a dropdown list of Report type and IG type.
b. Changes to Widget Parameters to Suffice Workflow Deployment and apt Dashboard View.
- Added empty file function to check if csv files exist in source location, if not then upload source files with just headers in source location.
- Cloud watch and IAM role – removed usage of AWS secrets and replaced it with IAM role.
Data Ingestion Pipelines – Claims
- Converted all the notebooks into wheel packages, removing any reference to HMNY.
- Added Cloudwatch library from common function repo
- Added filenames to cloudwatch exceptions
- Added default file generator
- Parameterized FHIR converter repartitioning
- Parameterized cloudwatch occurrence in all the files.
- Removed Coalesce when writing the file.
- Reading source files using a read function instead of reading a parquet file.
- Added empty file generator generates empty files in sourcefile location.
- Parameterized Spark Catalog for metadata.
- Added jobworkflow Entry points prefixed with IG to avoid Wheel Library ambiguity.
- Added API Key access credentials for Firely Upload.
- Removed Pyodbc occurrence.
Data Ingestion Pipelines – Clinical
- Converted all the notebooks into wheel packages, removing any reference to HMNY.
- Added Cloudwatch library from common function repo.
- Added default file generator – Clinical version of exiting the notebook if preprocess file is not present.
- Parameterized FHIR converter repartitioning.
- Parameterized CloudWatch occurrence in all the files.
- Removed Coalesce when writing the file.
- Reading source files using a read function instead of reading a parquet file.
- Added Spark Catalog instead of default metadata.
- Removed Path check as none of the profiles are interdependent.
- Added 500 error check in Upload Individual records.
- Added jobworkflow Entry points prefixed with IG to avoid Wheel Library ambiguity.
- Added API Key access credentials for Firely Upload.
- Removed sourcefile check.
- Modified FhirPrep and templates by adding references related changes.
- Removed Pyodbc occurrence.
Data Ingestion Pipelines – Provider Directory
- Converted all the notebooks into wheel packages, removing any reference to HMNY.
- Added Cloudwatch library from common functions
- Added filenames to cloudwatch exceptions
- Added default file generator - PVD Version of exiting the notebook when Preproc file is not present
- Parameterized FHIR converter repartitioning
- Parameterized cloudwatch occurrence in all the files.
- Removed Coalesce when writing the file.
- Reading source files using a read function instead of reading a parquet file.
- Added Spark Catalog instead of default metadata.
- Removed Path check as none of the profiles are interdependent.
- Added jobworkflow Entry points prefixed with IG to avoid Wheel Library ambiguity
- Added API Key access credentials for Firely Upload.
- Removed sourcefile check
- Added resource status update before Main
- Removed Pyodbc occurrence.
Data Ingestion Pipelines – Formulary
- STU-2.0 Data Guide creation
- STU 2.0 coding and sample file generation
- Added support for 2 profiles i.e., Formulary Drug (MedicationKnowledge), Formulary (InsurancePlan) in ingestion pipeline from scratch.
- Folder structure InitScript created from scratch.
- Formulary STU 2.0 specific Workflow creation.
- Added logic in preprocessing to resolve references to other resources.
- Added template based FHIR JSON creation for FormularyDrug and Formulary profiles.
- Fhir converter, Upload, Upsert, Upload individual records functionality added in the ingestion pipeline.
- Parameterized FHIR converter repartitioning
- Added Cloudwatch logging functionality from common functions.
- Added default file generator for landing files.
- Parameterized FHIR converter repartitioning.
- Parameterized Cloudwatch log channel occurrence in all the files.
- Removed Coalesce when writing the file.
- Reading source files using a read function instead of just reading a parquet file.
- Added parameterization of Unity Catalog instead of default spark catalog.
- Added api-key based authentication to Firely FHIR Server.
- Added IG specific entry points in JobWorkflow and setup files.
- Removed Pyodbc occurrence.
OnyxOS 5.3
Provider Directory (Plannet) 4.2
PREPROC CHANGES (4.2)
-
Json input file to csv conversion after applying necessary transformations and adding required columns (new columns to get reference FHIR IDs). Updating common cross walk table to maintain the FHIR IDs and its Business Identifiers references for all the profiles. Audit log and Error logs are included to log any error records or duplicates.
Notebook Added – all the notebooks in Preprocessing folder.
-
Creating required DBFS folder structure and tables in the data bricks.
Notebook Added - Conditional-InitScript
-
A new common notebook was added to get the spark session for all the preprocessing notebooks.
Notebook Added – SparkSession
-
Merging multiple files related to specific profile into a single file for that profile and then renaming the file to
.json. Notebook Added – DBFSRename
Main changes (v3.4)
-
import library statement changes to rename of package from “mainlibrary” to “pvdmainlibrary“.
Notebook Updated – for all the main notebooks.
-
Library Changes - as below
a. Update the methods read_configkey(), RetryProfile(), getSAFHIRInfoErrorDescription() for reading the config.ini file as the folder names got changed from ProviderDirectory to PVD and Config to config, now the new path got changed from /dbfs/FileStore/tables/ProviderDirectory/Config/{filename} to /dbfs/FileStore/tables/PVD/config/{filename}
Notebook Updated – commonfunctions
b. Path got updated for the folder name changes as mentioned above which got used for app log purposes
Notebook Updated – SAFHIR_Log_Actions
c. Method generateAudtiLog(), generateAuditLogForJson() got updated for the fix of UniquerowCount.
Notebook Updated – preprocAuditErrorLogging
d. Update the method updateResourceStatus() to use the ProfileName along with FHIRid for matching conditions before making the update to SQL table [reference].[PVD.ResourceStatus].
Notebook Updated – SQLHelper
e. Updated dbConnectGetTableDataAsDF and FhirPrepTrans functions to connect to DB and fetch the data on version and client type.
Notebook Updated – FhirPrepTransformations
f. Updates UpdateResourceStatus to only update the version of the FHIR PaaS in the database table when the resource is successfully uploaded to the FHIR PaaS.
Notebook Updated – SQLHelper
-
Templates Changes - as below a. Updated the template to map new columns for all profiles and to display reference business identifier when its corresponding FHIR ID is not found in the database crosswalk Table.
Notebook Updated – all the files in ‘Templates/FHIR_V1.0/ReleaseV1.1’ Folder.
-
Common Changes - as below
a. Added the logic to delete the GlobalsFile and attached it as task with jobworkflow.
Notebook Added – DeleteGlobalsFileb. Dbfs folder name got changed to PVD from ProviderDirectory for the same we have updated the below notebooks regarding the new path:
i. CopySFTPtoDBFS ii. CleanAuditErrorLog iii. Copy_Sharepoint_to_DBFSc. Dbfs folder name got changed to config form Config for the same we have updated the below notebooks regarding the new path:
i. CleanAuditErrorLog ii. Copy_Sharepoint_to_DBFSd. DeleteFhirRecords file addition
i. In this file we are deleting the FHIR PAAS Records from the Server based on the meta tag. ii. We also clear the ResourceStatus Table based on ClientType. -
MainPipeline Changes - as below
a. UniqueRow Count update for the notebooks where we are creating the FHIR resource bundles.
Notebook Updated – Fhir-prep, FHIR_Prep_Transformb. Added preprocessing file check before going for upload and upsert.
Notebook Updated – UploadUpsertWrapperc. Added notebook to check for the input file and execute preprocessing notebook and FHIR Converter.
Notebook Added – Preproc_FP_FCWrapperd. FHIR Converter error log addition
i. In this, we have added the intermediate Logging step where if the source file contains an Array type element the initial count will be higher than the source file. After merging the records with the same identifier, we will get the actual source file count. So, we have added a logging step over here to track the count at each step.
Database
- Using the same SQL server for all the consolidated clients with new individual client specific database setup as below metadata_v1_
for client - SQL script got updated to alter the table [reference].[PVD.ResourceStatus] for the primary key constraint now using the composite primary key as FHIRid and ProfileName instead of just FHIRid
FHIR PASS
- Using the same FHIR pass for ingestion purposes for all consolidated clients for one adb instance we are using one common FHIR pass (internal).
-
Introduced the meta.tag.display info for all the resources which are getting ingested to FHIR pass.
Notebook Updated – all FHIR-PREP notebooks where we are creating FHIR bundles.
JobWorkFlow
- Jobworkflow json code got updated to add the task to delete all the global variables related parquet files. New task got added as DeleteGlobalsFile as a last task into the workflow updated json file – pvdmainlibrary/JobWrkFlow-V3_2.json.
- Jobworkflow json code got updated with latest data flow. All the parallel tasks have been removed. Preprocessing, FHIR Converter, Upload and Upsert sequential for all the profiles.
Config.ini
-
Introducing parameterization for key – value pairs of config.ini file to handle the data file location which is different for internal and client environments.
a. data_file_path_
_pvd b. db_name_
c. pvd_main_notebook_path
d. pvd_preproc_notebook_path_
- key- value pair which got updated: updated the path regarding new folder changes (workspacae and dbfs) accordingly.
- Database consolidation
- Fhir pass consolidation.
FHIR-PAAS-CRED
- Added Structure Key Value Pair which will be used In the DeleteFhirRecords notebook.
- Parameterized the Partition Count value which be used in the FHIR Convertor.
Claims (CarinBB) v4.3
PreProc changes
-
All new preprocessed notebook got created with the logic to convert the given json file into the csv files as preprocessed landing file with basic preprocessing like null check and duplicate check.
Notebook Created – 7 new notebook got created as Claims, ClaimsDiagnosis(this has been extracted from the claims file ),Coverage,MemberMeta(no member meta we have it as empty notebook for the sake of jobworkflow activity ),Organization,Patient,Practitioner
-
Below are the details of header which got used for null check and duplicate check
Profile Duplicate Check Null Check Patient “I_UniqueMemberId” “I_UniqueMemberId”,”Patient name” Practitioner “UniqueId” “UniqueId”,”Provider_Name” Organization “I_PayerId” “I_PayerId”,”Name” Coverage “Identifier” “Identifier” ClaimsDiagnosis “Identifier” “Identifier” Claims “Identifier” “Identifier”,”PatientRef”,”ProviderRef”,”Claims_Coverage_ref” MemberMeta NA NA -
Source File Merge Logic – merging the multiple set of json files into one single file and renaming them accordingly.
Notebook – Rename_SourceFile
-
Empty Source File Creation for the profile for which we don’t have related source file and stop the e2e execution if there are no source files present post copying them to DBFS.
Notebook - SourceFileCheck
Main repo changes
-
For all Profile –
a. Version = ‘1.1.0’ got added to all the profile url for uscore one.
b. Notebook exit command got added to all of the transformation notebook.
c. System url value changes as per the given list by the CHGSD.
-
Patient
a. identifier – Having multiple identifier -now we have four identifiers which are mapped for these Identifier.type.code – MB,MA,MC,um out of these four using the ‘um’ one as business identifier.
b. Address –
i. using the type value as coming from the source files instead of hardcoding them to physical ii. adding up the new period mapping with start and end details into it. iii. Removing the use mapping specifically for CHGSD.c. Extension –
i. Removed the gender-identity extension specifically for CHGSD. ii. Added the new system url, when the race extension code is ‘UNK’ or ‘ASKU’.d. Telecom –
i. new element ‘rank’ got added.e. Communication – new mapping got added.
f. deceasedBoolean – new mapping got added.
g. Active – this mapping got removed specifically for CHGSD.
-
Coverage
a. Identifier
i. System url changed for chgsd ii. text, coding mapping removed specifically for CHGSDb. payor
i. reference to organization removed the _history details from the urlc. subscriber
i. using the subscriber_id instead of CPCDSMemberId for subscriber reference and removing the subscriber mapping specifically for CHGSDd. class
i. not displaying the class mapping if group_id, plan_identifier value is not available. -
Practitioner a. Identifier –
i. Now displaying the three identifier details which are tax, npi and unique id ii. Code customization to use the unique id as business identifier for CHGSD and for other clients using the npi as business identifier. -
Organization
a. Identifier –
i. Three identifier in total getting used for identifier mapping which are payerid, npi id , tax id ii. Payerid is getting used as business identifierb. Telecom
i. Added the new mapping for fax ii. New element ‘rank’ got added for both of the telecom mappingc. Address
i. Removed the use element specifically for CHGSD for all of the address mapping ii. New mapping got added for the address of type homed. Active
i. Instead of hard coding of active value as true we are now using the value which is coming from the source filese. Type
i. Removed the type mapping specifically for CHGSDf. Contact
i. Removed this particular mapping specifically for CHGSD. -
EOB
a. Identifier
i. System url fix as per the new shared valueb. Payment
i. Fix for comparing the payment_status_code for pariallypaidc. Related
i. System url got changed as per the shared system url valued. Payee
i. Added the new reference mapping based on the reference type either ‘Organization’ or ‘Practitioner’ or ‘Patient’ we are populating the reference detailse. Provider
i. Reference mapping has been changed to populate the reference based on the given reference type either ‘Practitioner’ or ‘Organization’ instead of hardcoding mapping to ‘Practitioner’f. Patient
i. System url value got changedg. Item.NoteNumbers
i. New mapping got addedh. Item.adjudication
i. New adjudication mapping got added for ‘inoutnetwork’i. Total
i. New mapping got added for ‘inoutnetwork’j. Suppportinginfo
i. Multiple fixes have been made for ‘perfomingnetworkcotractingstatus’,’servicefacility’ ii. valuereference new element has been added for ‘claim received date’ doing the reference to organizations. iii. New mapping for ‘drg’,’pointoforigin’ has been added.k. Careteam
i. Reference mapping has been changed for all the careteam now using the given value for reference which is either ‘Organization’ or ‘Practitioner’ instead of fixed reference to either practitioner or organization. ii. New careteam mapping has been added for ‘supervisor’, ‘operating’,’attending’, ‘otheroperating’. iii. For attending we have two mappings now.l. processNote – new mapping for process note has been added.
m. Created – instead of hardcoding to current_date() using the value which is coming from the source file specifically for CHGSD.
n. Subtype – added the new subtype mapping.
Client Apps(SLAP, FITE, Developer portal, Clarity, MoveMyHealthData(MMHD))
Hot fixes
-
Search parameter issue
Issue: Error while querying FHIR resources for claims with some of the search parameters.
Search parameters and resources to be supported:
Query to the FHIR server and error message:
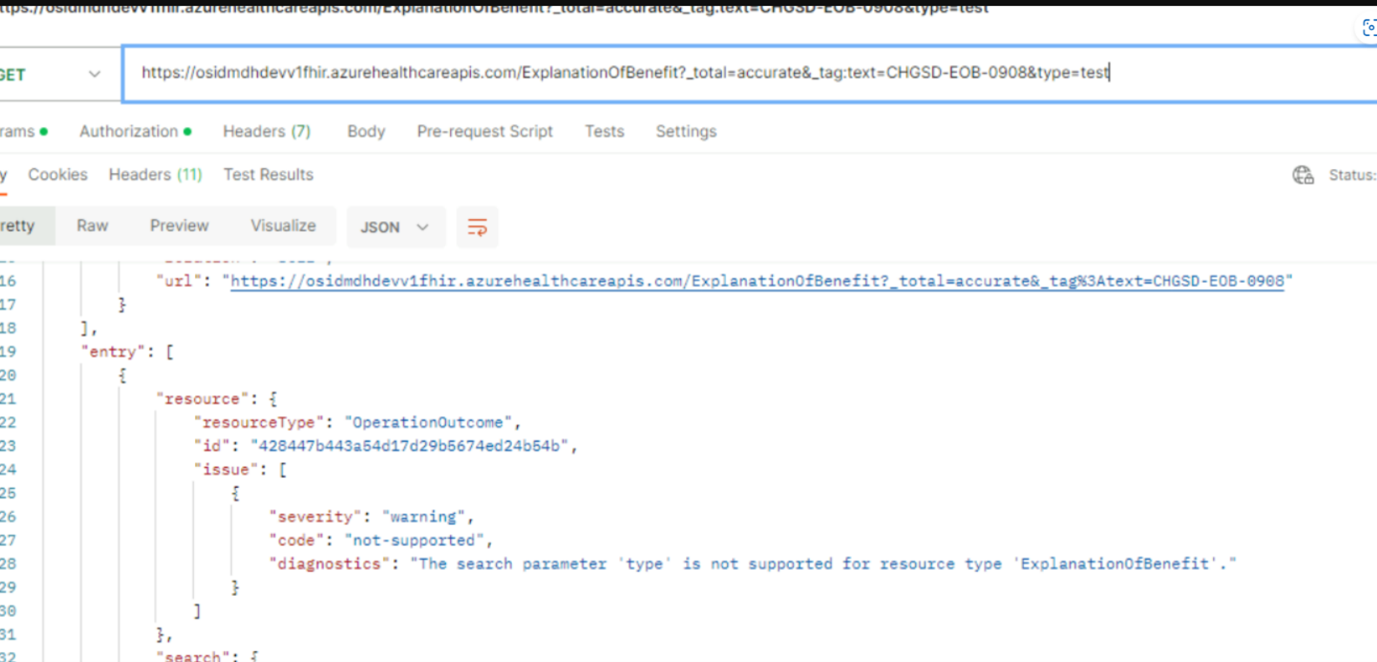
Resolution:
1. Remove the unsupported base resources from the SearchParameter resource and upload the updated resource. 2. Reindex the FHIR server. ( https://learn.microsoft.com/en-us/azure/healthcare-apis/fhir/how-to-run-a-reindex)